Sentiment analysis tools to explore the customers' emotions within the texts
Sentiment Analysis aims at obtaining meaningful information and semantics from a text, by using natural processing techniques and determining the writer's attitude, whether positive, negative, or neutral.
Positive
If you are positive about things, you are hopeful and confident.
-
Think of the good aspects of a situation rather than the bad ones
-
Showing satisfaction level of experience by positive adjectives
-
Indicating good feeling about the process and service
Negative
expressing or meaning a refusal or denial.
-
Detecting sadness, hate, violence and inadequacy about a new product
-
Showing emptiness and usefulness about the service or process
-
Drastic changes need to be made
Neutral
Neither good nor bad, neutral comments aren't helping your reputation, but they aren't hurting it either.
-
Sign of concern since the customer can quickly turn to the positive or negative
-
Not containing any definitive sentiment
What Is Sentiment Analysis?
Sentiment analysis is an automated tool capable of understanding the feelings or emotions that underlie texts such as comments. It is one of the most interesting subfields of NLP, a branch of Artificial Intelligence (AI) that focuses on how machines process human language. By digging deeper into these elements, the tool uncovers more context from your conversations and helps your customer service team accurately analyze feedback. This is particularly useful for brands that actively engage with their customers on social media, live chat, and email where it can be difficult to determine the sentiment behind a message.
Applications of Adopting a Sentiment Analysis Tool for businesses
Social media monitoring
There are more than 3.5 billion active social media users; that’s 45% of the world’s population. Every minute users send over 500,000 Tweets and post 510,000 Facebook comments, and a large amount of these messages contain valuable business insights about how customers feel about products, brands, and services.
Brand monitoring
Besides social media, online conversations can take place in blogs, review websites, news websites, and forum discussions. Product reviews, for instance, have become a crucial step in the buyer’s journey. Consumers read at least 10 reviews before buying, and 57% only trust a business.
Sentiment analysis is an excellent tool to keep a close eye on your brand’s reputation, find out what is right or wrong about your business, and understand more about your customers.
Customer support analysis
Providing outstanding customer service experiences should be a priority. After all, 96% of consumers say great customer service is a key factor to choose and stay loyal to a brand.Fortunately, sentiment analysis can help you make your customer support interactions faster and more practical.
If you run sentiment analysis on all your incoming tickets, you can easily notice the most dissatisfied customers or the most urgent issues and prioritize them above the rest. In addition, you could forward tickets to the appropriate person or team in charge of dealing with them.
Customer feedback analysis
By using sentiments analytics regarding specific features of your product, you’ll find out what customers respect and oppose most about your product. Once your sentiment analysis process is up and running, you’ll also be able to compare results with previous comments and see how sentiments toward aspects of your product have improved over time.
Market research
To collect insights on customer feelings, experiences, and needs relating to a marketing campaign for a new product release, Sentiment analysis can help monitor online conversations about specific marketing strategies, so you can see how it’s performing.
How Does Sentiment Analysis Work?
The sentiment analysis algorithm determines if a chunk of text is positive, negative or neutral. It uses natural language processing (NLP) techniques such as part-of-speech tagging, lemmatization, prior polarity, negations, and semantic clustering.
Part-Of-Speech tagging (POS tagging)
Part-of-speech (POS) tagging is a popular Natural Language Processing process which refers to categorizing words in a text (corpus) in correspondence with a particular part of speech, depending on the definition of the word and its context.
Learn More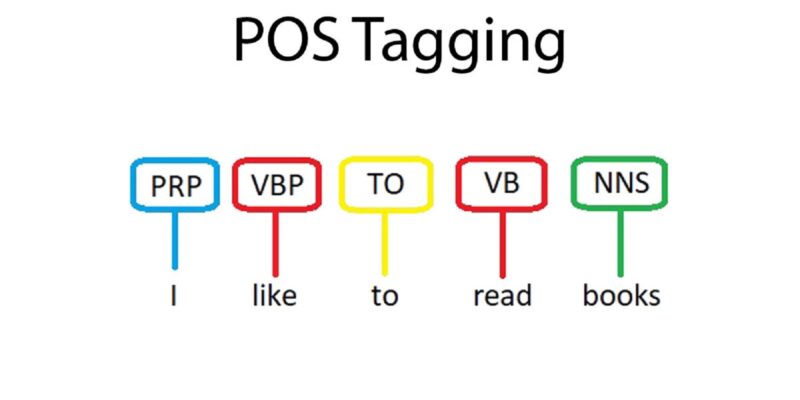
Lemmatization
In lemmatization, we try to reduce a given word to its root word. The root word is called a stem in the stemming process, and it is called a lemma in the lemmatization process.
A lemmatization algorithm would know that the word better is derived from the word good, and hence, the lemme is good. Because lemmatization involves deriving the meaning of a word from something like a dictionary, it’s very time consuming. So most lemmatization algorithms are slower compared to their stemming counterparts. There is also a computation overhead for lemmatization, however, in an ML problem, computational resources are rarely a cause of concern.
Test for Free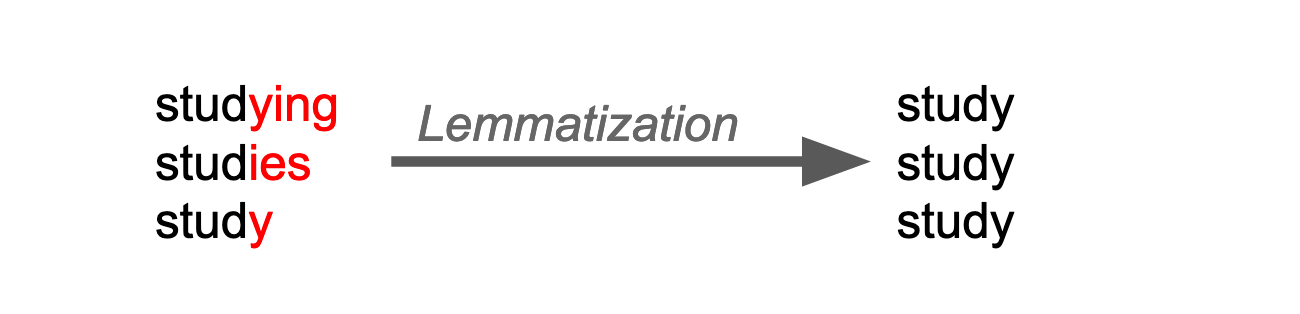
36.5 trillion
paragraphs comments tranied in our machine learning models.500 million
keyword phrases extracted23
languages supported in analytics insights- The value of sentiment analysis in growing your business
- Sentiment Analysis on YouTube Comments With Comments Analytics
- Machine Learning And Classification
- Text Processing And Data Cleaning
- Sentiment Analysis And Feedback
- Text Analysis And Nlp Techniques
- Keyword Extraction And Data Collection