

In a world overflowing with data, harnessing the information hidden within it has become an imperative for individuals, businesses, and society as a whole. Machine learning, a subset of artificial intelligence, has emerged as a transformative force in this quest for knowledge extraction. Within the realm of machine learning, classification stands as a cornerstone, enabling the categorization and prediction of data. In this comprehensive exploration, we delve into the fascinating world of machine learning and classification, deciphering the key concepts, algorithms, and practical applications that make it an indispensable tool in today’s data-driven landscape.
AI Text Classifier
“Machine learning and classification are the twin pillars upon which the edifice of artificial intelligence stands.” — John McCarthy
In a world where information is constantly being generated and shared through various digital channels, the ability to automatically categorize and understand textual data is paramount. This is where AI text classifiers come into play. These intelligent systems employ a wide range of machine learning algorithms to analyze and categorize text data, making sense of the vast amounts of unstructured information available on the internet.
AI text classifiers have found applications in diverse fields, from spam email filtering to sentiment analysis in social media. One notable example is the development of chatbots that can engage in natural language conversations with users, thanks to their ability to classify and respond to text inputs effectively. These systems have revolutionized customer support and user interactions in countless industries, offering efficient and personalized responses.
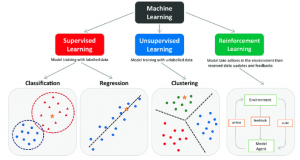
Machine Learning Classification Algorithms
“Machine learning is the science of getting computers to act without being explicitly programmed.” — Andrew Ng
Machine learning classification algorithms are the heart and soul of classification tasks. They enable computers to learn from data and make predictions or decisions without being explicitly programmed for each task. These algorithms form the backbone of countless applications, from recommendation systems that suggest products based on user behavior to autonomous vehicles that recognize objects in real-time.
One of the most famous classification algorithms is the Naive Bayes classifier, named after the Bayesian probability theory. This algorithm is particularly useful for natural language processing (NLP) tasks such as spam email detection and social media post sentiment analysis. By analyzing the probability of each word or feature appearing in a particular category, the Naive Bayes classifier can classify text documents with remarkable accuracy.
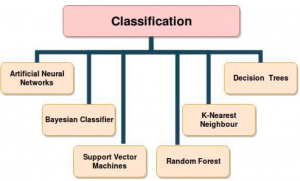
Classification Machine Learning
Classification in machine learning extends beyond text data processing. It encompasses a wide array of applications, from medical diagnosis to image recognition and fraud detection. These classification tasks aim to sift through vast amounts of data and make informed decisions, saving time and reducing errors compared to human-driven processes.
One of the powerful tools in the classification toolbox is Support Vector Machines (SVMs). SVMs are known for their ability to handle complex data with a high degree of accuracy. They work by finding the optimal hyperplane that best separates data into distinct categories, making them particularly useful in scenarios where data is not linearly separable. SVMs have been instrumental in fields such as image recognition, where objects need to be identified within complex visual environments.
Naive Bayes Classifier Example
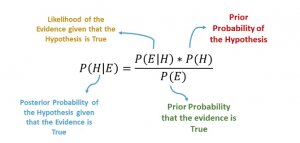
Let’s delve deeper into the world of text classification by exploring a practical example of the Naive Bayes classifier in action. Consider a scenario where you want to build an email spam filter. This filter needs to classify incoming emails as either spam or not spam based on their content.
The Naive Bayes classifier can help achieve this with remarkable accuracy. It operates on the principle of conditional probability. By analyzing a large dataset of labeled emails, the classifier calculates the probability of each word appearing in a spam or non-spam email. When a new email arrives, it computes the likelihood of the email being spam or not spam based on the words it contains and selects the category with the highest probability.
SVM Benefits Overview: The Power of Margin
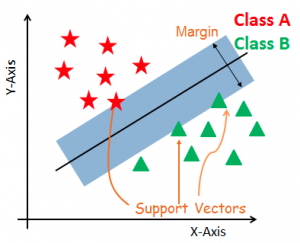
Support Vector Machines (SVMs) are a versatile and powerful tool in classification. They excel in scenarios where data is not easily separable using linear boundaries. SVMs work by finding the hyperplane that maximizes the margin between different categories of data points.
One of the key benefits of SVMs is their ability to handle high-dimensional data efficiently. This makes them ideal for tasks like image classification, where each pixel in an image constitutes a dimension. SVMs have been successfully employed in medical image analysis to detect diseases such as cancer from complex and multi-dimensional medical images.
Certainly! One compelling example of the importance of Support Vector Machines (SVM) in machine learning is their application in medical diagnosis, specifically in the detection of diseases such as breast cancer.
Breast cancer is a prevalent and life-threatening disease that affects millions of people worldwide. Early detection is crucial for effective treatment and improved survival rates. SVMs have played a pivotal role in developing highly accurate and efficient diagnostic tools.
Here’s how SVMs are applied in this context:
- Data Collection: Researchers gather data from various sources, including medical images such as mammograms, patient histories, and clinical tests. This data is used to create a dataset with features related to breast cancer, such as the size and shape of tumors.
- Data Preprocessing: Before feeding the data into an SVM model, it undergoes preprocessing steps like normalization, feature selection, and handling missing values. This ensures that the data is clean and suitable for training.
- Training the SVM: The SVM model is trained on this preprocessed dataset, using labeled examples where each example is categorized as either benign (non-cancerous) or malignant (cancerous). The SVM’s goal is to find the optimal hyperplane that maximizes the margin between these two classes while minimizing classification errors.
- Testing and Validation: After training, the SVM is tested on a separate dataset that it has never seen before. This testing dataset helps evaluate the model’s performance. SVMs often achieve high accuracy in distinguishing between benign and malignant tumors.
- Real-world Application: Once the SVM model is validated and proven to be accurate, it can be deployed in clinical settings. Medical professionals can use it to assist in the early detection of breast cancer by analyzing mammograms or other relevant medical data. SVMs provide a valuable second opinion, helping to reduce false positives and false negatives, which are crucial in cancer diagnosis.
The significance of SVMs in medical diagnosis extends beyond breast cancer and includes the detection of various diseases and conditions, such as diabetes, heart disease, and neurological disorders. The ability to make accurate predictions and classifications based on complex medical data has the potential to save lives and improve the quality of healthcare.
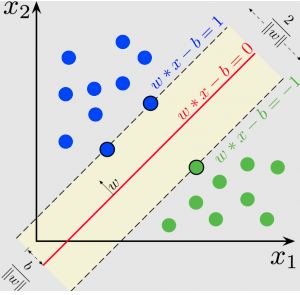
SVM Explained
To gain a deeper understanding of Support Vector Machines, let’s explore how they work. Imagine a scenario where you need to classify animals into two categories: cats and dogs. You have data points representing these animals based on two features: size and fur length. The task is to find a hyperplane that separates cats from dogs as accurately as possible.
SVMs work by finding the hyperplane that maximizes the margin between the two classes. In this case, the margin represents the distance between the closest data points (support vectors) from each class to the hyperplane. By maximizing this margin, SVMs ensure that the classification is as robust as possible, even in the presence of outliers or noise in the data.
Naive Bayes NLP
Natural Language Processing (NLP) is a subfield of machine learning that focuses on enabling computers to understand, interpret, and generate human language. Within NLP, the Naive Bayes classifier plays a crucial role in tasks such as sentiment analysis, language translation, and chatbot interactions.
In sentiment analysis, for example, the Naive Bayes classifier can determine whether a given piece of text expresses a positive, negative, or neutral sentiment. This capability is invaluable for businesses seeking to understand customer opinions and reviews, as well as for social media platforms aiming to identify and moderate harmful content.
Classification Models: From Theory to Practice
“Machine learning is the most transformative technology in human history.” — Erik Brynjolfsson
Machine learning classification models serve as bridges between theory and practical applications. These models are the result of training algorithms on labeled data, enabling them to make accurate predictions or classifications on new, unseen data. The choice of the model depends on the nature of the data and the specific problem at hand.
In addition to SVMs and Naive Bayes, there are numerous other classification models, each with its own strengths and weaknesses. Decision trees, for instance, are widely used for their interpretability and ease of visualization. Random forests, on the other hand, combine multiple decision trees to improve accuracy and reduce overfitting.
Classifier Algorithms: Diving Deeper into Data
Classifier algorithms are at the core of machine learning classification tasks. These algorithms, ranging from the simple to the complex, are designed to identify patterns and relationships within data, allowing them to make informed decisions. As the complexity of the problem increases, so does the need for advanced classifier algorithms.
One remarkable aspect of classifier algorithms is their adaptability to different domains. Whether you’re classifying images of celestial bodies in astronomy or diagnosing diseases from medical images, classifier algorithms can be fine-tuned and tailored to the specific characteristics of the data.
ML without Coding
The democratization of machine learning has been a transformative trend in recent years. ML platforms and tools that require little to no coding have made it possible for individuals without extensive programming backgrounds to harness the power of machine learning.
These no-code or low-code ML platforms provide user-friendly interfaces that guide users through the process of data preprocessing, model selection, training, and evaluation. They empower subject matter experts in various fields to create and deploy machine learning models for their specific needs, from financial analysts building predictive models to healthcare professionals diagnosing diseases.
No-Code ML: Bridging the Gap Between Experts and Algorithms
No-code ML platforms have the potential to bridge the gap between domain experts and machine learning algorithms. They enable experts in fields such as finance, healthcare, and marketing to leverage the power of AI without needing to become proficient programmers.
Imagine a marketing analyst who wants to predict customer behavior based on historical data. With a no-code ML platform, they can simply upload the data, select the target variable (e.g., purchase likelihood), and let the platform handle the rest. The platform will automatically preprocess the data, choose an appropriate model, train it, and provide predictions, all through a user-friendly interface.

Training Data vs. Test Data:
In the journey of building a machine learning model, the distinction between training data and test data is of paramount importance. The training data is used to teach the model patterns and relationships within the data, while the test data is used to evaluate the model’s performance on unseen examples.
The quote “garbage in, garbage out” aptly captures the essence of machine learning model training. If the training data is biased, incomplete, or unrepresentative of the real-world data, the model’s predictions will be flawed. Therefore, data preprocessing and curation are critical steps in the machine learning pipeline.
Machine Learning Excel: Crunching Numbers for Insights
Machine learning doesn’t always require specialized software or programming languages. In fact, it can be accomplished using everyday tools like Microsoft Excel. Excel’s powerful data analysis capabilities, combined with machine learning add-ins and plugins, make it accessible to a wide range of users.
With Excel, users can perform tasks such as data cleaning, feature engineering, and even building and evaluating simple machine learning models. This approach is particularly valuable for business professionals who are already familiar with Excel and want to leverage its capabilities for data-driven decision-making.
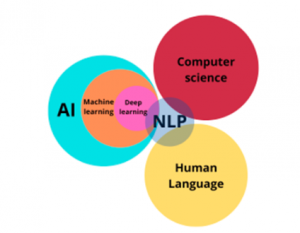
AI/ML/NLP: A Triumvirate of Transformative Technologies
Artificial intelligence (AI), machine learning (ML), and natural language processing (NLP) form a triumvirate of transformative technologies that are reshaping industries and societies. AI encompasses the broader goal of creating intelligent agents capable of reasoning, problem-solving, and learning. ML is the subset of AI that focuses on teaching machines to learn from data. NLP, on the other hand, deals specifically with human language understanding and generation.
This convergence of AI, ML, and NLP has led to groundbreaking advancements, from self-driving cars that use machine learning to navigate to virtual assistants like Siri and Alexa that employ NLP to understand and respond to voice commands. As these technologies continue to evolve, their impact on our daily lives and industries is only expected to grow.
Conclusion: Empowering the Future with Machine Learning and Classification
“Machine learning and classification are the twin pillars upon which the edifice of artificial intelligence stands.” — John McCarthy
In a world inundated with data, machine learning and classification are the guiding lights that enable us to extract knowledge and insights from the chaos. From the simplicity of Naive Bayes classifiers to the complexity of Support Vector Machines, the tools and algorithms at our disposal continue to evolve, making the once-unimaginable possible.
The democratization of machine learning through no-code platforms empowers individuals and experts alike to tap into the transformative potential of AI. With the ability to classify, predict, and make decisions at scale, machine learning and classification are poised to shape the future of industries, healthcare, finance, and beyond.
As we navigate this data-driven world, it’s essential to remember that the power of machine learning and classification lies not just in the algorithms and tools but in our ability to harness them responsibly and ethically. With great power comes great responsibility, and as we stand at the crossroads of this technological revolution, the choices we make will shape the course of our future.
I know this website presents quality dependent posts and
additional information, is there any other website which presents
such stuff in quality?
https://maste-ru.ru/
Eager to enhance your online security seamlessly? Our freelance services provide you covered! From strengthening your website against unwanted visitors to facilitating file sharing, we’ve got straightforward solutions for all. https://skillset.surge.sh
Hi there
Just checked your commentsanalytics.com baclink profile, I noticed a moderate percentage of toxic links pointing to your website
We will investigate each link for its toxicity and perform a professional clean up for you free of charge.
Start recovering your ranks today:
https://www.hilkom-digital.de/professional-linksprofile-clean-up-service/
Regards
Mike Stanley
Hilkom Digital SEO Experts
https://www.hilkom-digital.de/
Hi there,
I have reviewed your domain in MOZ and have observed that you may benefit from an increase in authority.
Our solution guarantees you a high-quality domain authority score within a period of three months. This will increase your organic visibility and strengthen your website authority, thus making it stronger against Google updates.
Check out our deals for more details.
https://www.monkeydigital.co/domain-authority-plan/
NEW: Ahrefs Domain Rating
https://www.monkeydigital.co/ahrefs-seo/
Thanks and regards
Mike Freeman
Hi
I have just took an in depth look on your commentsanalytics.com for its SEO Trend and saw that your website could use a push.
We will improve your ranks organically and safely, using only state of the art AI and whitehat methods, while providing monthly reports and outstanding support.
More info:
https://www.digital-x-press.com/unbeatable-seo/
Regards
Mike Brown
Digital X SEO Experts
Экспертные рекомендации по покупке SLS принтера
sls 3d принтер купить https://www.pgrt3d-lss.ru/ .
Лучшие магазины
Выбор 3D принтера для промышленного использования
3d принтер промышленный купить http://www.prm-3dinter.ru .
Сравнение цен на slm принтеры в различных магазинах
slm 3d принтер купить http://ptrlmms-3d.ru/ .
Eco-Friendly Living
The Power of Solar Panels for Your Mobile Home
mobile home with solar panels https://larpan-mobi4omes.ru .
Get Started with Solar Power
The Benefits of Using Solar Panels for Camping
solar power panels for camping https://stport-solarpanels.ru/ .
pharmaceutical online ordering
Never Run Out of Power with This Solar Generator for RVs
generator vs solar for rv https://argener-rv4.ru/ .
3D сканеры в продаже: выбор и покупка
3 в сканер купить https://www.3scnrd65.ru .
Лучшие предложения на 3D принтеры по металлу
купить 3d принтер по металлу https://met3f-int43.ru/ .
online pharmacy dubai
metformin 500mg canada
Upgrade Your Camping Experience
Stay Charged on the Road with the Perfect Solar Generator for Your RV
Discover the Best Solar Generator for Your RV
solar generator for rv air conditioner https://www.ghkolp-56dert.ru .
buy cialis no prescription
Stay Powered Up
Portable and Efficient: The Best Solar Generators for Home Backup
solar powered home backup generator https://olargener-ackup.com .
mexican pharmacy online
azithromycin online order usa
canadian pharmacy prices
lisinopril 2.5 mg tablet
which online pharmacy is the best
PBN sites
We create a network of privately-owned blog network sites!
Advantages of our privately-owned blog network:
We execute everything so Google DOES NOT comprehend that THIS IS A private blog network!!!
1- We purchase web domains from separate registrars
2- The primary site is hosted on a VPS hosting (VPS is fast hosting)
3- The rest of the sites are on different hostings
4- We assign a distinct Google ID to each site with verification in Google Search Console.
5- We make websites on WP, we don’t utilize plugins with aided by which Trojans penetrate and through which pages on your websites are produced.
6- We do not reiterate templates and employ only exclusive text and pictures
We don’t work with website design; the client, if desired, can then edit the websites to suit his wishes
Выбор большого 3D принтера
3d принтер больших размеров http://lastyu-bigpech.ru/ .
Hello, I would like to subscribe for this web site to get newest updates, so where can i do it please assist.
https://englishmax.ru/