Named Entity Recognition: identifying key information (Entities) in the text
Named entity recognition (NER) is a natural language processing (NLP) technique that automatically identifies named entities in a text and classifies them into predefined categories. Entities such as names of people, organizations, locations, times, quantities, etc.
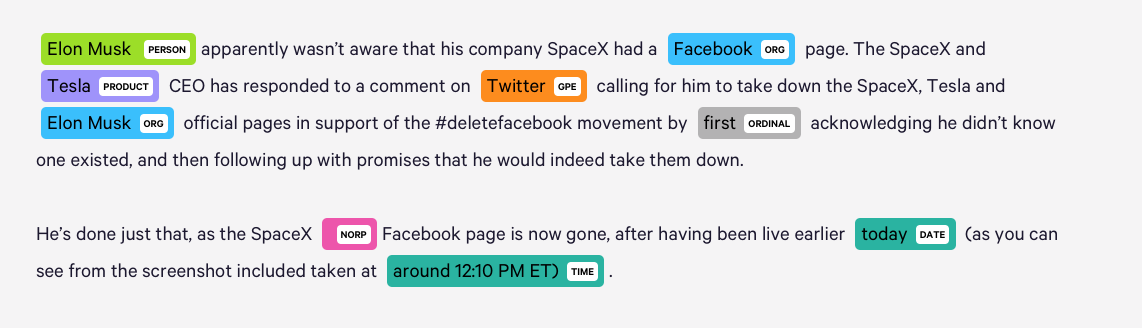
What is named entity recognition (NER) and how can it use?
Named entity recognition (NER) that sometimes referred to as entity chunking, extraction, or identification, is the task of identifying and categorizing key information (entities) in text. An entity can be any word or series of words that consistently refers to the same thing. Every entity is classified into a predetermined category. With named entity recognition, you can extract key information to comprehend what a text is about, or use it to collect important information to store in a database.
NER is a form of natural language processing (NLP), a subfield of artificial intelligence. NLP is concerned with analyzing natural language, i.e., any language that has developed naturally, rather than artificially, such as with computer coding languages.
NER is used in many fields in Natural Language Processing (NLP), and it can help answering many real-world questions, such as:
-
What is the importance of social network analysis?
-
Were specified products mentioned in comments?
-
Does the tweet contain the name of a person? Does the tweet contain this person’s location?
Top 5 approaches to Named Entity Recognition (NER):
Rule-based
Rule-based systems are usually based on hand-crafted rules written by individuals. These rules can be based on patterns in the text or syntactic structure. While rules can be very practical in some fields, they can be challenging to develop and maintain.
Statistical models
Statistical models are based on the idea that named entities can be distinguished from other words in the text. Several statistical models have been developed for NER, including hidden Markov models (HMMs), maximum entropy (Maxent) models, and support vector machines (SVMs). These models can be effective, but they often require large number of training data.
Neural networks
Neural networks (NN) are a subset of machine learning approaches that used for NER. Neural networks are well-suited for this kind of analysis because they can learn complex patterns in data. However, neural networks require a large amount of training data to learn these patterns.
Hybrid systems
these are approaches that combine multiple approaches to NER. In some cases, a system may use a rule-based approach to identify person names and a statistical approach to identify organizations. Hybrid systems can be effective because they can use each approach’s strengths.
Semantic role labeling
Semantic role labeling (SRL) is a related task that aims to identify each word’s role in a sentence. This is usually done by analyzing the syntactic structure of the sentence and the context of the entity in the sentence.
Word embedding
Word embedding is also called word representation or distributed representation. It learns vector representation for every word appearing in the corpus. The one-hot representation uses a vocabulary-sized vector and takes a 1 when the word appears in the document and a zero when it does not. Word embedding reduces the dimensions and sparseness of the original vector and fills the vector with real numbers.