

In today’s data-driven world, the volume of information generated and collected is expanding at an unprecedented rate. Businesses, researchers, and organizations rely heavily on data to make informed decisions and gain valuable insights. However, before data can be analyzed or used effectively, it often requires a series of critical preprocessing steps, with text processing and data cleaning being integral components of this journey. In this comprehensive guide, we will delve deep into the world of text processing and data cleaning, exploring the importance of these processes, the strategies involved, and providing real-world examples and solutions.
Data Preprocessing Steps
Data preprocessing is the foundational step in the data analysis pipeline. It encompasses various operations aimed at transforming raw data into a format suitable for analysis. Before diving into text-specific preprocessing, it’s crucial to understand the broader context of data preprocessing.
One famous quote by Ronald Coase, a Nobel laureate in economics, highlights the importance of data preprocessing: “If you torture the data long enough, it will confess to anything.” This adage emphasizes the significance of thorough data preprocessing in ensuring that the data is reliable and trustworthy.
Data preprocessing typically involves tasks such as data cleaning, transformation, and reduction. It is essential for handling missing values, outliers, and inconsistencies. Popular techniques include data imputation, scaling, and normalization. These steps lay the groundwork for effective text processing and data cleaning, ensuring that the data is primed for analysis.
Data Cleaning and Preparation
“Data preparation is the most important step in the analytical process. Data munging, or the cleaning and preprocessing of data, can take up to 80% of an analyst’s time.” — Hadley Wickham, Chief Scientist at RStudio
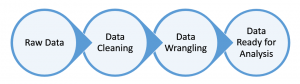
Data cleaning is a vital component of data preprocessing. It focuses on identifying and rectifying errors and inconsistencies in the data. These errors can arise from various sources, including human entry, measurement inaccuracies, or data transfer issues. To illustrate the importance of data cleaning, consider the words of John Tukey, a renowned statistician: “An approximate answer to the right problem is worth a good deal more than an exact answer to an approximate problem.”
Data cleaning involves tasks such as handling missing values, dealing with duplicate records, and correcting data types. In the context of text data, this includes tasks like removing irrelevant characters, correcting spelling errors, and standardizing text format. For example, in a dataset containing customer reviews, data cleaning might involve removing special characters, converting all text to lowercase, and eliminating HTML tags from web-scraped content.
Data Cleansing Strategy
Developing a robust data cleansing strategy is essential to ensure that the data cleaning process is systematic and effective. Without a clear plan in place, it’s easy to overlook critical issues in the data. A well-structured strategy should consider the specific characteristics of the dataset and the objectives of the analysis.
In the words of the renowned management consultant Peter Drucker, “What gets measured gets managed.” This principle applies to data cleansing as well. Before diving into data cleaning, it’s crucial to define clear criteria for identifying errors and inconsistencies. This can involve creating data quality metrics and setting thresholds for acceptable data quality.
Moreover, automation plays a significant role in data cleansing. Tools and scripts can be employed to streamline the process, making it more efficient and less error-prone. A good data cleansing strategy also includes provisions for regular data audits and maintenance to ensure data quality remains high over time.
Data Wrangling Examples
Data wrangling is a term often used interchangeably with data cleaning and preparation. However, data wrangling encompasses a broader set of tasks that includes not only cleaning but also reshaping and transforming data to make it suitable for analysis. It involves operations like merging datasets, aggregating data, and creating new features.
To put it into perspective, consider the words of Hadley Wickham, a prominent statistician and data scientist: “Data wrangling, which is often 80-90% of the work of data science, is a huge bottleneck in the data analysis process.” Wickham’s statement underscores the significant role data wrangling plays in the data analysis pipeline.
Let’s delve into a real-world example of data wrangling. Imagine you have two datasets—one containing customer information and another with purchase history. Data wrangling in this context might involve merging the two datasets based on a common identifier, calculating summary statistics like total spending per customer, and creating new variables to segment customers by their purchasing behavior.
Data Cleaning in Data Science
“Data cleaning is like dealing with the noise before you can enjoy the music. It’s the unglamorous yet essential part of the data science process that ensures your insights are based on quality data, allowing you to extract the symphony of knowledge hidden within.”
In the realm of data science, data cleaning is a fundamental step that can greatly impact the quality and reliability of the models and insights derived from the data. As the famous statistician George E. P. Box once said, “All models are wrong, but some are useful.” Data cleaning aims to make the data more “useful” by reducing inaccuracies and biases.
Data scientists often encounter messy data, and their success hinges on their ability to clean and preprocess it effectively. This process includes handling outliers, dealing with imbalanced datasets, and addressing class imbalance in machine learning tasks.
In text data, data cleaning takes on a unique set of challenges. Cleaning text involves removing stopwords, stemming or lemmatizing words, and handling text encoding issues. For example, when analyzing social media data, data scientists may need to deal with slang, abbreviations, and emojis in text data. Effective text cleaning is essential to extract meaningful insights from such unstructured text.
Unstructured Data Examples
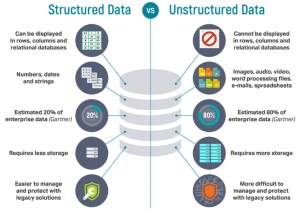
Unstructured data refers to data that lacks a predefined structure, making it challenging to analyze using traditional methods. Examples of unstructured data include text documents, images, audio recordings, and social media posts. Taming this wealth of unstructured data is a critical aspect of modern data analysis.
In the words of Douglas Laney, an industry analyst, “Unstructured data is like raw material waiting to be processed.” To make sense of unstructured data, it must undergo text processing and data cleaning. Let’s explore some real-world examples of unstructured data and how text processing can be applied:
Social Media Posts:
Social media platforms generate an enormous amount of unstructured text data. To extract insights from these posts, text processing techniques like sentiment analysis can be applied to gauge public opinion and sentiment toward specific topics or brands.
Legal Documents:
Legal documents often contain extensive text with complex language and legal jargon. Text processing can be used to extract key information, such as case summaries, from lengthy legal documents, making legal research more efficient.
Medical Records:
Medical records are another example of unstructured data, often consisting of physician notes, patient histories, and test results. Text processing can assist in extracting patient information, identifying trends in medical conditions, and automating the classification of medical records.
Unstructured Data Management Solutions
Managing unstructured data can be a daunting task, but there are solutions and strategies to tackle this challenge effectively. As Victor Mayer-Schönberger, a professor of internet governance and regulation, stated, “Big data is like teenage sex: everyone talks about it, nobody really knows how to do it, everyone thinks everyone else is doing it, so everyone claims they are doing it.” Unstructured data management is indeed a topic frequently discussed, but it requires careful consideration and action.
Text Mining and Natural Language Processing (NLP):
Text mining and NLP techniques play a pivotal role in managing unstructured text data. These approaches involve tasks such as tokenization, part-of-speech tagging, and named entity recognition to extract valuable information from text.
Document Management Systems:
Document management systems provide structured repositories for unstructured data. They allow for efficient storage, retrieval, and organization of documents, making it easier to access critical information when needed.
Content Management Platforms:
Content management platforms are designed to handle unstructured content, such as web pages and articles. They offer tools for categorization, indexing, and search, enabling businesses to harness the value of textual content.
Text Vectorization
Text vectorization is a crucial step in text processing that transforms text data into numerical form. This transformation is necessary because most machine learning algorithms and statistical models require numerical input. Text vectorization involves converting words or phrases into vectors, making it possible to perform mathematical operations on the data.
To quote the computer scientist and pioneer in artificial intelligence, John McCarthy: “Programming a computer for natural language understanding and generation is a difficult problem.” Text vectorization is a key component of solving this difficult problem. Here are some common text vectorization techniques:
Bag of Words (BoW):
BoW represents text as a collection of unique words in the corpus and their frequencies. Each document is represented as a vector, with each dimension corresponding to a word in the vocabulary. BoW is simple but effective for many text classification tasks.
Term Frequency-Inverse Document Frequency (TF-IDF):
TF-IDF is a numerical statistic that reflects the importance of a term within a document relative to a corpus. It is widely used for information retrieval and text mining tasks, helping to identify significant terms in a document.
Word Embeddings:
Word embeddings, such as Word2Vec and GloVe, capture the semantic relationships between words by mapping them to dense vector spaces. These embeddings have revolutionized natural language processing tasks by enabling algorithms to understand word context and meaning.
Text Processor
Text processing is the backbone of many modern applications, enabling machines to comprehend and work with human language. From search engines delivering relevant results to sentiment analysis gauging public opinion, text processing underpins countless aspects of our digital lives. It’s instrumental in information retrieval, machine translation, chatbots, and even summarizing vast amounts of text. In essence, text processing empowers technology to bridge the gap between the human world of language and the computational world of data, making it a fundamental field in today’s data-driven society.
A text processor is a software tool or system that facilitates the manipulation and analysis of textual data. It serves as the backbone of text processing and data cleaning tasks. Just as a carpenter relies on a quality set of tools, data analysts and scientists depend on text processors to work efficiently with textual information.
The words of the computer scientist and co-founder of Sun Microsystems, Vinod Khosla, underscore the importance of effective text processing tools: “The next big software company won’t be a software company at all.” This statement highlights the notion that the most valuable tools in the data-driven era may not be traditional software but specialized data processing tools.
Text processors come in various forms, from simple text editors to powerful natural language processing libraries and platforms. Some popular text processors include:
Python’s Natural Language Toolkit (NLTK):
NLTK is a comprehensive library for text processing and NLP in Python. It provides tools for tokenization, stemming, lemmatization, and various NLP tasks.

SpaCy:
SpaCy is a fast and efficient NLP library for Python, known for its speed and accuracy in tasks like named entity recognition and part-of-speech tagging.
Text Editor Software:
Basic text editors like Notepad, Sublime Text, and Visual Studio Code are often used for manual text cleaning and processing tasks.
Text Wrangling
Text wrangling, also known as text munging, refers to the process of transforming and preparing text data for analysis. It encompasses tasks such as cleaning, tokenization, and feature engineering. Effective text wrangling is essential for extracting valuable insights from textual information.
As Andrew Ng, co-founder of Google Brain and an influential figure in the field of artificial intelligence, aptly put it: “AI transformation is not about changing 10% of the company; it’s about changing 100% of the company.” In the context of text wrangling, this transformation involves adapting data and processes to leverage the full potential of textual data.
Let’s explore some essential aspects of text wrangling:
Tokenization:
Tokenization involves breaking text into smaller units, such as words or phrases (tokens). This step is crucial for various NLP tasks, as it defines the granularity of analysis.
Stemming and Lemmatization:
Stemming and lemmatization are techniques for reducing words to their root forms. These processes help in standardizing text and reducing dimensionality in text data.
Feature Engineering:
Feature engineering is the art of transforming raw data into meaningful and predictive features, and it stands as one of the foundational pillars of machine learning and data science. While algorithms and models often take the spotlight, it’s the quality and relevance of the features that can make or break a predictive system. Effective feature engineering involves selecting, creating, or transforming features to highlight the underlying patterns in the data. It’s akin to crafting a precise tool for solving a specific problem, enabling models to grasp complex relationships and improving their accuracy and robustness. Without thoughtful feature engineering, models may struggle to extract meaningful insights from data, underscoring the critical role it plays in turning data into actionable knowledge.
Feature engineering in text data involves creating new features that capture important information. For instance, in sentiment analysis, features may include word frequency or sentiment scores.
Clean Text
Clean text is the ultimate goal of text processing and data cleaning efforts. Clean text is free from noise, inconsistencies, and unnecessary information, making it suitable for analysis and modeling. Clean text is the foundation upon which meaningful insights and valuable information can be built.
To quote the data scientist and author of “Python for Data Analysis,” Wes McKinney: “Data munging and cleaning is where most of a data scientist’s time is spent.” McKinney’s statement highlights the significant effort required to transform raw text data into clean, analyzable text.
Achieving clean text involves a combination of data cleaning, text preprocessing, and text wrangling techniques. It requires careful attention to detail and a thorough understanding of the specific domain and objectives of the analysis.
Cleaning Data in Python
Python is a popular language of choice for data cleaning and text processing tasks. Its rich ecosystem of libraries and tools makes it a versatile platform for handling text data. Whether you’re dealing with structured data or unstructured text, Python offers a wide range of resources to simplify the data cleaning process.
The words of Guido van Rossum, the creator of Python, capture the essence of Python’s appeal for data cleaning: “Python is an experiment in how much freedom programmers need. Too much freedom and nobody can read another’s code; too little and expressiveness is endangered.” Python’s balance between flexibility and readability makes it a powerful tool for data cleaning and processing.
Here are some Python libraries and tools commonly used for data cleaning and text processing:
Pandas:
Pandas is a widely used library for data manipulation and analysis. It offers data structures like DataFrames that simplify tasks like handling missing values and filtering data.
NLTK (Natural Language Toolkit) and SpaCy:
As mentioned earlier, NLTK and SpaCy are essential libraries for text processing and NLP in Python. They provide a wide range of NLP functionalities.
Regular Expressions (Regex):
Regex is a powerful tool for pattern matching and text manipulation. It is invaluable for tasks like finding and replacing specific text patterns in data.
Clean Big Data
Cleaning big data presents unique challenges due to the sheer volume and complexity of the data. As the data scientist and author DJ Patil noted, “The best data scientists are also not afraid to get their hands dirty with messy data.” Cleaning big data often involves distributed computing frameworks and specialized tools to handle the scale of the data.
Here are some strategies and considerations for cleaning big data:
Distributed Processing:
Leverage distributed computing frameworks like Apache Hadoop and Apache Spark to clean and preprocess big data efficiently. These frameworks provide the scalability needed to handle massive datasets.
Data Sampling:
“Data sampling is the compass that guides us through the vast ocean of data. It allows us to navigate and explore, revealing patterns and insights that would otherwise remain hidden. Sampling is the art of extracting meaningful knowledge from the data universe.”
When dealing with enormous datasets, it’s often impractical to clean the entire dataset at once. Data sampling techniques can be used to work with manageable subsets of the data for initial cleaning and analysis.
Parallel Processing:
Utilize parallel processing techniques to clean data in parallel across multiple processors or nodes. This approach speeds up the cleaning process for large datasets.
Text Extraction API
Text extraction APIs are valuable tools for automating the extraction of text from various sources, such as documents, images, and websites. These APIs employ advanced techniques like optical character recognition (OCR) and natural language processing to extract text accurately.
As Jeff Bezos, the founder of Amazon, once stated: “We’ve had three big ideas at Amazon that we’ve stuck with for 18 years, and they’re the reason we’re successful: Put the customer first. Invent. And be patient.” Text extraction APIs put the customer first by simplifying the process of obtaining structured text data from unstructured sources.
Here are some common use cases and examples of text extraction API applications:
Extracting Text from Images:
Text extraction APIs can convert text contained within images or scanned documents into machine-readable text. This is invaluable for digitizing printed material and automating data entry.
Extracting Data from PDFs:
Many documents are stored in PDF format, which may contain text, tables, and images. Text extraction APIs can extract text and structured data from PDFs, making it easier to analyze and use this information.
Web Scraping and Content Extraction:
- Web scraping and content extraction play a pivotal role in today’s data-driven world. The importance of these techniques lies in their ability to transform the vast and unstructured information available on the internet into actionable insights. From monitoring competitors and market trends to gathering research data and automating data acquisition, web scraping empowers businesses and researchers with a wealth of real-time and historical data. It allows for the aggregation of data from diverse sources, enabling decision-makers to make informed choices and gain a competitive edge. Furthermore, content extraction helps in distilling valuable information from websites, making it accessible and usable for analysis, research, and decision-making. In essence, web scraping and content extraction serve as the gateway to a wealth of information, unlocking opportunities for innovation, strategy development, and data-driven decision-making in various fields.
Text extraction APIs can be used to scrape text content from websites, news articles, and blogs. This is particularly useful for aggregating data or monitoring online trends.
Extractor Business
The extraction of valuable information from unstructured data sources has become a lucrative business opportunity. Companies and startups specializing in text extraction services offer solutions to organizations looking to harness the potential of unstructured data.
In the words of Bill Gates, the co-founder of Microsoft, “Your most unhappy customers are your greatest source of learning.” Extractor businesses leverage feedback from their customers to continuously improve their text extraction services, ensuring accuracy, reliability, and scalability.
Extract Example
To illustrate the capabilities of text extraction services, let’s consider an example. Imagine a financial institution that receives hundreds of customer emails containing various types of documents, such as bank statements, invoices, and tax forms. Extractor businesses can develop customized solutions to automatically extract relevant information from these emails and documents.
The process involves using text extraction APIs to convert the contents of emails and attached documents into structured data. This structured data can then be integrated into the institution’s database for further analysis and processing. By automating this process, the financial institution can save time, reduce errors, and provide a more efficient customer experience.
Extract Keywords from Website
Extracting keywords from websites is a common text extraction task, especially for search engine optimization (SEO) and content analysis. Keywords are essential for understanding the main topics and themes of a website’s content.
Text extraction APIs can crawl websites and extract keywords from the textual content of web pages. These keywords can be used to optimize website content, improve search engine rankings, and gain insights into the most relevant topics discussed on the site.
Extract Phone Numbers
Extracting phone numbers from unstructured text data is a valuable task for businesses in various industries, including customer service, sales, and marketing. Phone numbers extracted from text can be used for lead generation, customer outreach, and contact management.
Text extraction APIs equipped with regular expression patterns can identify and extract phone numbers from text documents, emails, or web pages. The extracted phone numbers can then be stored in a structured format for easy access and use.

Extractor Tool
Extractor tools are software applications or platforms that provide a user-friendly interface for text extraction tasks. These tools often integrate text extraction APIs and offer additional features for customization and data management.
Extractor tools are valuable for users who may not have programming expertise but need to perform text extraction tasks efficiently. These tools typically provide a graphical user interface (GUI) that allows users to specify extraction parameters and view extracted data in real time.
In conclusion, text processing and data cleaning are indispensable steps in the data analysis pipeline. They transform raw, unstructured data into clean, structured information that can be used for analysis, modeling, and decision-making. As data continues to grow in volume and complexity, the importance of text processing and data cleaning cannot be overstated.
To quote the data scientist and author Dan Ariely: “Big data is like teenage sex: everyone talks about it, nobody really knows how to do it, everyone thinks everyone else is doing it, so everyone claims they are doing it.” In the realm of data analysis, it’s not enough to talk about big data; we must also excel at the critical tasks of text processing and data cleaning to unlock the true potential of the information at our disposal.
As we’ve explored in this comprehensive guide, data preprocessing steps, data cleaning and preparation, data cleansing strategy, and data wrangling examples are essential components of effective data processing. Unstructured data examples and solutions, text vectorization, text processors, and text wrangling techniques provide the tools needed to manage and analyze unstructured text data. Clean text, cleaning data in Python, and cleaning big data are essential skills for data scientists and analysts.
Text extraction APIs, extractor businesses, and practical examples of text extraction tasks demonstrate how text processing extends beyond data analysis into automation and business solutions. As the field of data science and analytics continues to evolve, mastering the art of text processing and data cleaning will remain a cornerstone of success in deriving meaningful insights from data.