

Text data is all around us, from social media posts to research articles, and news headlines to product reviews. Understanding the hidden structures and meanings within text can be a daunting task, but it’s an essential one in today’s data-driven world. In this article, we’ll delve into the fascinating realms of Topic Modeling and Semantic Analysis, two powerful techniques that enable us to extract valuable insights from textual data.
Topic Modeling
“Words are a lens to focus one’s mind.” — Ayn Rand
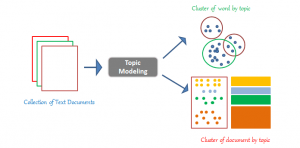
Imagine being able to identify the underlying themes or topics in a massive collection of documents without reading each one individually. That’s precisely what Topic Modeling allows us to do. At its core, Topic Modeling is a machine learning technique that discovers the recurring patterns of words in a text corpus, clustering them into topics. Each topic represents a group of words that tend to co-occur frequently in the same documents.
For example, in a collection of movie reviews, Topic Modeling might reveal topics like “Plot and Storytelling,” “Acting and Performances,” and “Visual Effects.” By uncovering these hidden themes, businesses can gain insights into customer feedback, researchers can categorize vast amounts of literature, and content creators can optimize their strategies.
Real-World Example:
One prominent application of Topic Modeling is in news categorization. News agencies can use it to automatically classify articles into topics like “Politics,” “Sports,” or “Entertainment,” allowing for efficient content management and retrieval.
Aspect-Based Sentiment Analysis
“The meaning of words is in their use.” — Ludwig Wittgenstein
While Topic Modeling helps us identify broad themes, Aspect-Based Sentiment Analysis takes a deeper dive into text to understand the nuanced opinions and sentiments expressed. It goes beyond mere positive or negative sentiment classification and identifies specific aspects or features within a text and the sentiments associated with each of them.
Consider a product review for a smartphone. Aspect-based sentiment Analysis can pinpoint aspects like “Battery Life,” “Camera Quality,” and “Performance,” assessing whether the sentiment expressed towards each aspect is positive, negative, or neutral. This fine-grained analysis provides businesses with actionable insights for product improvement and customer satisfaction.
Real-World Example:
Restaurants often use Aspect-Based Sentiment Analysis to analyze customer reviews. They can identify specific aspects like “Food Quality,” “Service,” and “Ambiance” in reviews and gauge customer sentiment towards each aspect, helping them make targeted improvements.
Semantic Analytics: Beyond Words
Semantic Analytics takes text analysis to a higher level by understanding the meaning and context behind words. It doesn’t merely rely on word frequency but also considers the relationships between words and their contextual significance. This technique leverages Natural Language Processing (NLP) and Machine Learning to extract semantic information from text.
For instance, while traditional methods might flag a sentence containing the word “fire” as a potential hazard, Semantic Analytics can determine whether it refers to a campfire in a positive context or a building fire in a negative one. This deeper understanding is invaluable in applications such as sentiment analysis, content recommendation, and search engine optimization.
Theme Finder for Text:
Theme Finder for Text is a tool that assists in identifying recurring patterns and themes within a body of text. It’s often used in content analysis and text mining to reveal common themes, trends, or motifs present in a collection of documents.
For instance, a Theme Finder applied to a set of financial reports might uncover recurring themes like “Profitability,” “Market Trends,” and “Risk Assessment.” This can help financial analysts and investors quickly identify key insights from a large dataset.
Real-World Example:
In marketing, Theme Finder for Text can be employed to analyze customer feedback across various channels and discover recurring themes in customer complaints or compliments. This information can guide product improvements and marketing strategies.
Text Keyword: Unlocking Significance
“The difference between the right word and the almost right word is the difference between lightning and a lightning bug.” — Mark Twain
Keywords are the building blocks of text analysis. They are the words or phrases that carry significant meaning and can serve as identifiers of topics or concepts within a text. Identifying and analyzing text keywords is essential in various applications, including search engine optimization, content tagging, and document summarization.
For instance, in a news article about climate change, keywords like “global warming,” “carbon emissions,” and “climate crisis” are critical for understanding the article’s main focus. Analyzing these keywords and word clouds can help in categorizing and summarizing the content effectively.
In the field of e-commerce, businesses use text keywords to tag products and make them discoverable through search queries. Accurate keyword tagging enhances the user experience by ensuring relevant search results.

Topic Data
Topic Data refers to the structured information derived from topic modeling and semantic analysis. It encapsulates the essence of the underlying themes, sentiments, and patterns within textual data. This data serves as the foundation for generating actionable insights, making informed decisions, and driving improvements.
For instance, a market research firm might use topic data to analyze customer reviews of a particular product category, uncovering the most discussed features and sentiments. This information can guide product development and marketing strategies for businesses in that industry.
Social media platforms like Twitter use topic data to curate trending topics and hashtags, providing users with real-time insights into current events and discussions worldwide.
Analyzing Topics: A Data-Driven Approach
“Data is a precious thing and will last longer than the systems themselves.” — Tim Berners-Lee
Analyzing topics is the heart of text analysis. It involves exploring the identified topics in-depth, understanding their significance, and drawing actionable conclusions. This process requires combining data science techniques, domain knowledge, and critical thinking.
For instance, in a political context, analyzing topics within news articles can reveal emerging trends and public sentiments. Understanding these topics can help political analysts and policymakers make informed decisions.
Real-World Example:
During a health crisis like the COVID-19 pandemic, analyzing topics in news and social media can help health organizations understand public concerns and misinformation trends, allowing them to respond effectively.
Topic Identification
Topic Identification is the process of assigning meaningful labels or categories to the topics identified in textual data such as Youtube comment categorization. It’s a crucial step in making the results of text analysis interpretable and actionable.
For example, in a collection of customer reviews, topic identification might label topics as “Product Quality,” “Customer Service,” and “Shipping Experience.” These labels make it easier for businesses to understand the main areas of concern and focus on improvements.
Real-World Example:
Topic identification is widely used in market research to classify consumer feedback into specific categories for analysis and decision-making.
Topic Modeling Algorithms
Topic modeling algorithms are the computational engines that power the discovery of topics within textual data. There are several popular algorithms in this domain, each with its strengths and weaknesses.
One well-known algorithm is Latent Dirichlet Allocation (LDA). LDA assumes that each document in a corpus is a mixture of topics, and each topic is a mixture of words. It uses statistical inference to reverse-engineer the topics from the documents.
Another widely used algorithm is Non-Negative Matrix Factorization (NMF). NMF factorizes the term-document matrix into two lower-dimensional matrices, one representing topics and the other representing document-topic assignments.
Topic modeling algorithms are applied in academic research to analyze and categorize large collections of research papers, helping researchers identify trends and gaps in knowledge.
This article provides an overview of the fascinating world of Topic Modeling and Semantic Analysis, touching on various aspects and real-world examples. While this article offers a glimpse into these topics, there’s much more to explore and uncover in the realm of text analysis. Whether you’re a researcher, a business owner, or simply curious about the power of words, these techniques can unlock a world of insights hidden within text data.